

Almost every company is using at least some cloud services today, and they’re not just using packaged SaaS apps, PaaS services and IaaS virtual machines. Websites and custom apps are built using application programming interfaces (API) for everything from mapping and messaging, to analytics, fraud detection and speech recognition.
Software-as-a-service (SaaS) offerings often offer APIs that let you work with them through third-party apps and services, or even build your own. For example, more than 50 percent of Salesforce’s traffic — and revenue — comes through its APIs, rather than directly from its own Web-based service. For eBay, it’s 60 percent, and for Expedia it’s 90 percent. If you use Twilio for sending text messages for customer support or MasterCard fraud detection services, you’re relying on those APIs for your own key business processes. How do you measure and monitor them to find out if you’re getting an acceptable level of service?
Just because you’re using a cloud service, you can’t assume it will perform well. Outages are rare, and you can use geo-redundancy to make sure your cloud app fails over to another region if service in one region goes down. But while SLAs with vendors of hosted systems cover uptime, they rarely make any mention of latency. Too much latency, and your API calls will time out, creating a poor experience for your users and customers.
Microsoft encountered a problem like that when it started moving its Bing search engine to continuous deployment and started measuring some external dependencies for the first time, says Craig Miller, a Bing technical adviser at Microsoft. “We found services we were using where we didn’t realize the reliability wasn’t more than three nines,” he says.
You may not even know how many APIs and SaaS apps are in use across your company, now that many business units are buying their own cloud services, so you might want to start using tools that tell you what’s active in your network. Such offerings include Microsoft’s Azure Cloud App Discovery or Imperva’s Skyfence. This is particularly important if you have services that you inherited from a predecessor or acquired in a merger — you need to find out what you’re taking on.
[Related: APIs abound, but challenges remain]
But once you know, you need to do more than keep an eye on the status alerts for the services and APIs you’re relying on; and you can’t assume that SLAs will cover every conceivable problem.
API gateways — which can be cloud services like the Amazon API Gateway, Apigee API Gateway, Tibco's Mashery API manager and Micorosoft’s Azure API Management system, or on-premises API managers like those available from Akana, Layer7 and 3scale — let you control access to APIs, and manage resources by policy, rate limit clients and see usage analytics. Some, like Azure API Management, function as proxies that let you control internal usage of external APIs. But mostly, they're about packaging up and offering your own APIs and Web services, helping you scale, monitor and distribute them. That doesn't help you much when it comes to understanding the external APIs and microservices that you're probably using, often without measuring. And if you use a mix of internal and public APIs, you’ll want to think about monitoring those explicitly as well.
Latency and location
The question, according to David O’Neill, CEO of API analytics service APImetrics, is, “Who tells you about problems caused by APIs? Your dev and ops team, or your customers? Do you know what your infrastructure is doing for your customers end to end? You probably don’t, and if you did you’d be horrified.”
Working with APIs is more complex than many people understand, O’Neill maintains. “There are some really weird things people need to take into account that the industry is only just realizing,” he says. “We’ve created a new world of Web apps and services where companies have no idea about what they're paying for, if they're working and what they're actually doing. People [rely on SLAs], but they have SLAs that don’t have the right measures. SLAs talk about uptime; they don’t talk about latency or responsiveness.”
 Microsoft
Microsoft APImetric’s Insight score works like a credit score for an API, giving you a quick overview of performance and variability.
You can’t just look in your own logs, or run your own tests, to see how responsive APIs are, because the problems may not be visible there — they only tell you what performance you’ll see when you access the API from your network. You can’t even use one cloud location to test from. For example, “if you call the Foursquare API from the Azure region in Virginia, it will either fail or it can take up to 20 minutes to return any response,” O’Neill says. “But that’s only from Azure in Virginia; from Azure in California it works just fine.”
Simple logs and measurements won’t tell you everything, and you certainly can’t rely on average latency readings. If the average latency you’re seeing is, say, 250 milliseconds, you have to check to see if it includes some unusually fast responses masking the ones that take 5 or 10 seconds. Remember to think about the scale of API calls: If you only make 1,000 calls, a 99.6 percent success rate means there are only four failures, and that level of performance isn’t likely to cause problems. But if you make 1 million calls, that’s 4,000 failures. And when you start using multiple APIs from different services, you have to consider latency between them, too.
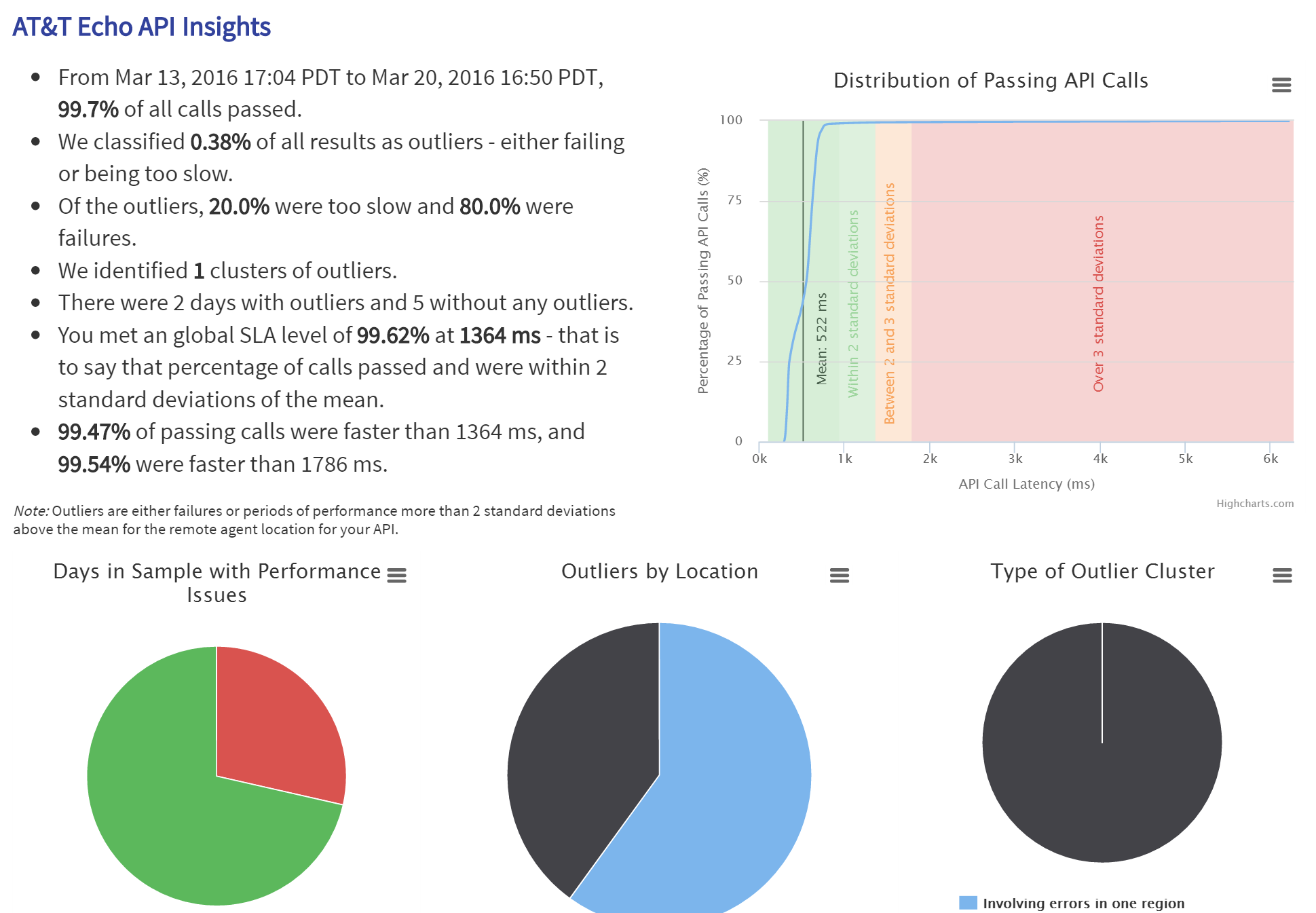 Microsoft
Microsoft Looking at a range of measurements and analyses gives you a clearer picture of API performance.
It gets worse when you have international customers. “If you’re measuring performance on your server, how are you going to measure that for customers in Japan? You can’t stick everything into AWS in Virginia and run a global service, but a lot of companies do just that,” O’Neill warns. “You have to look at it end to end. If you have Japanese customers and you’re in the East Coast AWS data center, there’s going to be latency because it’s just down to the speed of light how fast they can route a query. And if you’ve got three API calls behind the public one and each of them requires a transatlantic hop, that could be adding lots of latency. You won’t see that on your server — and your customer will not experience what you do.”
Join the CIO Australia group on LinkedIn. The group is open to CIOs, IT Directors, COOs, CTOs and senior IT managers.