Deduping in Salesforce: The complete how-to
- 31 August, 2017 20:00
Every enterprise system has the risk of data quality problems, but customer relationship management (CRM) and marketing automation systems are incredibly vulnerable to incomplete records, bad data, and duplicate records. Data comes from too many flaky sources, and there aren’t enough incentives for organizations and people to really follow standards. Fortunately, a number of services and tools have arisen to automagically improve data quality (in particular, Salesforce’s Data.com). When it comes to deduping, though, even the best tools out there need to be used with careful attention to detail and the prep work that can take days. We’ll show you how to avoid the main pitfalls here.
The big deal about dupes
Duplicate records are dangerous to system credibility because users can’t find the updates that they’ve made (they’re looking at the wrong copy of the record) and each of the dupes represents an incomplete record with multiple data quality issues. The longer a dupe exists, the more the data quality issues metastasize, making rectification ever more costly.
[ Find out how CRM buyers can negotiate the best deal, when Salesforce certifications matter & what to look for, and how to screen a Salesforce consultant. | Get the latest insights by signing up for our CIO newsletter. ]
Duplicate records are indicators of process problems, either in user training or because there something that makes the original record invisible or unusable for that user in a specific stage of the process. Dupes are also key indicators of system problems (Is the weekly upload not using fuzzy matching? Is this integration not properly checking for existing records? Is that trigger using the right logic to check for and resolve dupes before doing a record update?)
I hope I’ve scared you about this issue, because fixing it can require a surprising amount of time.
Prevention is the best cure
The starting and ending point of any deduping project is this: finding defects in processes and systems to prevent the creation of dupes in the first place. Step one is to identify which process and system elements are creating which flavor of dupe (and yes, you will have to do pattern recognition on the particular types of dupe you’re experiencing). Once you’ve done this, you need to have a brief checklist of situations to flag, with solution strategies for each one. For example:
- What do you do when two people share the same email address?
- What do you do when a person has 10 email addresses?
- What do you do when one company you do business with acquires another one that’s a prospect?
- What do you do with international divisions of conglomerates, some handled by your sales team and others handled by a channel partner?
These checklists of business rules need to go to your relevant developers and consultants so they know what to look for and build in handlers in their code.
[ If duplicate Lead and Contact issues are your top-level problem, "CRM's Identity Crisis: Duplicate Contacts" will help you think it through. ]
There are tools that help prevent dupes, but they are absolutely not created equal. For imports, you’re looking for five main attributes:
- Compatibility with your file formats (mostly, this is just XLS and CSV)
- Compatibility with the object/table you’re working with (there’s more to life than just leads and contacts)
- Matching on more than just a couple of fields
- Fuzzy matching of most fields
- Ability to configure the fuzzy parameters (hopefully, for each field)
For records created by real-time processes, there’s one additional attribute that has to be mentioned: how does the tool behave when a dupe is created by code or via a web-service call (e.g., SOAP or ReST)? Most tools block creation of such records, which might seem OK…that is, until you try to deploy a bug-fix and discover that you can’t because some piece of test code creates a duplicate record and prevents you from pushing anything into production. Sometimes, the only choice is to temporarily disable the dupe blocker, do the push, and then remember to re-enable the blocking system. Your developers and admins will thank you for buying a dupe preventer that is more forgiving and/or flexible in error handling.
There are three key thoughts before I go on. First, the best approach to processing imports is to do the deduping outside the system (before they get in)…and conversely, the best approach to removing existing dupes from the database is to do that inside the system (any dedupe sequence that requires an export-process-import cycle is almost certainly wrong). Second, there’s no universal answer to the question, “should we do data enrichment before the merge cycle, or after.” But typically, doing it after the merge is better (and it’s always safer and less work). And finally, the third thought that will drive Mac lovers nuts: you really want to be using the best tools, and those only run on a PC (even if you run Parallels on a Mac, you’ll need to get a PC keyboard and make sure everything is mapped properly). Also, it’s best if you have two or even three screens for doing the heavy lifting.
Where to start
The only place to start is to stop and think. Because you can’t do anything good without developing a strategy to fit your specific situation. And there are several situations where something that looks like a dupe actually isn’t one. Here are some examples:
- Companies that have the same name because they’ve been abbreviated (for example, Ford for Ford Motor Company and Ford for Ford Modeling Agency). Solution strategy: use official company names in the system-standard Account Name field to avoid confusion, and add a custom field on the company record to reflect “friendly” or “street” names.
- Companies with tons of divisions (think Mitsubishi or Tyco). Solution strategy: keep all the divisions as companies, but name them more appropriately and make the divisions as child accounts of the corporate parent (I like naming the parent like this: Company [stock symbol]).
- Companies with tons of international operations (think Volkswagen of America vs. Volkswagen do Brasil vs. Volkswagen de France). Solution strategy: name the companies completely and make them children of the “mother ship” (Volkswagenwerke AG).
- People who have left one company and joined another. Solution strategy: either rename the person as Joe Blow [former employee] or merge the two Joe Blows and add a Contact Role to Joe’s former employer indicating the former employee status (note that these choices have different implications about the way you manage your long-term relationships, so think through which is the closest match for how you want to see relationships over several years).
- Contracts that are obsolete or that went through several iterations before signature. If these need to be kept (and typically, old contracts should be kept for 7 years), the solution strategy should be to rename the obsolete ones to reflect their status (e.g., “BigCompany – 2015 replenishment [concluded]”).
- Cases that were re-opening a supposedly-resolved issue. Solution strategy: leave the cases (as “re-opens” are an important indicator of service quality), but rename the earlier avatars and provide a pointer to the final case in the series.
Once you have confirmed that you really have dupes, the next step is to develop a strawman set of criteria for the dupe-detection cycle. Some tools call this a “scenario,” others “matching rules,” but no matter what the nomenclature, the idea is to set up an algorithm that will catch 80 percent of the real dupes but have zero false positives (be willing to compromise on the 80 percent, but you have to have a zero tolerance policy for false positives at this point). The algorithm has to identify the “winner” record (the one that will survive), but errors on this detail aren’t too impactful. The best tools use a scoring system for determining the winner, so you can tune the weighting of various fields. You may discover the need to create new formula fields on the object to properly identify the winner (for example, isVP and isStrategic Booleans to make sure that important records get routed to important people).
Do not use the strawman criteria until you’ve tested them with a good-sized sample (using spreadsheets) and validated the results with the people who will be affected by the merges (e.g., marketing for Leads, sales for Contacts, Accounts, and Opportunities, and service for Cases and Contracts). If you have a full sandbox, use it for your tests! Of course, that won’t let you see the merge repercussions with integrated systems, but it’ll get you a long way.
Once you are satisfied with the strategies that capture dupes, you need to choose the merge parameters. The best tools let you select things like:
- Does a “winner” record’s blank values over-write a loser’s non-blank value?
- For text fields, does the loser’s text get concatenated to the end of the winner’s text?
- Are exceptions possible, where certain “loser” records’ fields trump the winners’?
The merge process in Salesforce.com (SFDC) preserves all “related lists” (child or related records) from both of the merged records. But for the fields within the two records being merged, only one value per field can be preserved. If you need to preserve or concatenate data from the “dying” record into the surviving one, you’ll have to do that with some supplemental steps after the fact (which means you need to do some prep work before the merge).
Integrated systems and plug-ins
This is where things get hairy. Let’s start with the simple stuff: plug-ins. Most plug-ins installed in SFDC don’t really mind deduping and probably won’t corrupt anything when you merge. But read that word “most” – you must test with your particular configuration of plug-ins to make sure nothing nasty happens.
Things get tougher with external systems, which may be integrated via a plug-in or a SOAP/ReST connector. The most valuable integrations are the trickiest:
- Marketing automation (MA) systems probably won’t pay attention when you merge most tables, but may throw a hissy-fit if you merge Leads and Contacts from within SFDC. The smarter MA systems will probably have their own merge features, so you’ll need to do those merges on the MA side of the integration. If your MA system doesn’t, contact your vendor’s support (or even consulting) team to ask for guidance.
- Accounting, billing, collections, e-commerce and other business operations systems probably will ignore the merges on most tables, but will freak out if you try to merge Accounts, closed Opportunities, Contracts, or related records. The external system may block the merge or may instantly recreate the dupe or all kinds of surprising things. The only way to know what’s going to happen is to read the vendor’s docs, reach out to their support/consulting team and do a test with dummy records in your production system. Note the word and in that sentence: you need to do all three steps with each system.
- Enterprise system buses, integration hubs and the like are the unpredictable Frankenstein because you probably don’t know what all the end-points are. In addition to the first two bullets’ considerations, you need to think about what will happen to data warehouses, web sites/portals, and even cash registers. Test with some fake records in production, then wait 48 hours and look at the error logs of the integration hub and key applications before doing anything with data of any value.
What if testing determines you can’t merge certain kinds of records? There are two general solutions: one is using record ownership fields and SFDC roles/sharing privileges to hide the dupes from most users (the admins and other apps must still see them), and the other is to modify the records’ Name field to indicate the “ignore this one” status (for example, “Company XYZ [do not use]” or “▼Joe Blow”) in reports and user screens.
Danger Will Robinson!
Deduping is such a tricky business that I have to stress these best practices:
- Never start a deduping session before completing a full system backup (all tables, really, every merge cycle).
- Do not allow regular users to do merges.
- Do not deploy triggers or classes that do merges unless you have done a code review to understand all the conditions under which the logic may fire, and make sure that the repercussions of such automated merges (including reverberations from systems integrated with SFDC) are reasonable.
- Almost never merge accounts.
- Do merges in small batches (typically less than 10 percent of the entire set of candidates in each pass) and pause a few hours to review the impact of the merges (listen for panicked calls from someone who’s lost their pet records or found some reason why your solution strategy is bogus).
- Document the strategies, parameters, thresholds and procedures used in each deduping session. Do not throw away log files that are generated by your deduping tool.
- Never do merges when you are stressed out, pressed for time or just plain tired.
Page Break
Preventing duplicate Salesforce records
Duplicate record prevention is a cute little topic, but it’s part of a much larger data quality topic. The big picture is embodied in this sentence: no record should be created without some level of procedural or automated controls. Those controls should help enforce data quality and fidelity concerns, including naming conventions and record ownership.
There are three major sources of records in a CRM system: user input, data imports and data integrations. Each of these needs to be managed differently, but with a coherent strategy.
Let’s start with the simplest case: user input. Ideally, every record in every object should be checked to make sure it isn’t a dupe. This can range from the brutal (duplicate names not allowed, via a data definition language constraint) or subtle (a fuzzy match on several criteria, with a warning message on-screen that allows the user to override the warning as needed. While users may not mind that much if things are brutal, code (including test code), imports, and integrations will mind a lot if the same brutality is applied without exception. Our recommendation is generally to move away from brutal measures and focus on warnings and follow-up emails beseeching the user to make sure the apparent dupe record has a business purpose. There are products in the Salesforce AppExchange that do a good job of this, or if you have really tricky needs you may have to write some code.
Record imports are a bit less cut-and-dry, but actually allow for the nicest outcomes. Typically, data imports have a number of data quality problems (such as formatting, capitalization and column-matching) in addition to being a source of potential dupes. For imports, you’ll want to resolve as many of the data quality problems as possible before you start deduping, as more-complete records mean better dupe detection. And, of course, you’ll want to dedupe within the import set before you dedupe between the import set and existing CRM data. Since you have time and freedom to test imports before the real import, you can make the cycle squeaky-clean.
Typically, import data sets do not have any kind of universal identifier (such as a D-U-N-S or social-security number), so you’re depending on fuzzy matching. Each source of external data will have its own optimal matching parameters (such as “how to clean account names of articles and punctuation” or “how country codes and city codes are handled in phone numbers”), and you’ll want to look at each batch of data carefully while setting the fuzzy-match parameters and scoring. Document each source so you can repeat the recipe next time. Most of the time, fuzzy matching products provide either a series of prioritized rules (first look for verbatim name, then fuzzy name, then phone number) or a set of scoring/weighting parameters. I happen to like scoring-based parameters, but both prioritized rules and scoring work well if you’re careful.
When it comes to Accounts and other tables, the CRM system is almost invariably the preferred point of import. In contrast, for Leads and Contacts, many marketing automation systems have their own importers, and the vendors often recommend you use them, rather than the CRM system’s. That's fine, but be aware that most marketing automation systems use only email addresses as the basis of deduping, and there isn’t much fuzziness or flexibility: if someone has multiple email addresses, they are often represented as multiple people. Consult with your marketing automation vendor about their recommended strategy for handling this.
Perhaps the hardest case for dupe prevention comes from data integrations between the CRM and outside batch or synchronous sources, because each of those sources needs to be considered separately—each requiring its own handler. Unfortunately, those handlers almost always have to be custom code embodied in the middleware or the source application itself. Typically, other applications or outside data feeds don’t know how to deal with an error generated by dupe detection/rejection in the CRM system. If you’re really lucky, the app will provide detailed error logs and have workflow managers that know how to put troublesome transactions and their dependencies into suspension until the underlying issue is resolved. If you’re somewhat lucky, the record (or the batch) will simply be rejected and thrown into the retry queue. If you’re not lucky, the record will simply be thrown into an error status and the external app’s errors will pile up indefinitely. Yum.
Obviously, the best strategy for external apps is for them to query SFDC for likely-dupe records before the external app tries to create the new record. If an appropriate match is found, the external app should simply do an update to the existing record. Some applications’ transaction managers will support this…but only some. Get ready for coding.
Page Break
Nipping dupes in the bud
We all make mistakes, and with certain extract, transform, load (ETL) and import cycles, big fat errors are just a mouse-click away. The problem is, with triggers and workflows, any SFDC insert or update may have tons of repercussions on other records. You can’t just delete the mistake, you have to look for all the places where it propagated and reverse that, too. Obviously, every situation is different, but here’s the basic strategy to undo the thing you shouldn’t have done.
- Send an email out to users telling them to ignore records created today not do updates to the system’s records until further notice. Yes, it’s very painful, but if you let them continue to update things, you may never unscramble the data.
- Figure out every table that was directly affected and do a backup of every field and every record in those tables.
- Go to the backup tapes – you DID do a backup before you started, right? And you DO have backup files, at least on a weekly basis, right? Get the most recent files for comparison/analysis.
- Don't start modifying anything until you understand the failure mode of what caused it. If you don't appreciate this properly, you will make erroneous deletes and be “unwinding” the wrong things, which is even more irritating and visible for the users.
- Do a bunch of tests to find out what your main dupe pattern is. Typically, they will all be created by the same user (you) at (almost) the same time. Look to see if there are any updates to any of those records since you created them — if you're lucky, there aren't any (so there's no information value there, and you don’t have to look for relevant updates). Look to see if there is a "last activity date" of today — if there isn't, that's a good thing.
- Do an extract of the IDs of every record that could be related (as a parent or child) to the object where there are dupes. For Accounts, this is, at minimum, contacts, tasks, opportunities/deals and notes. All you need of those tables is the record ID and the pointer back to the account. What you're looking for is records that may have been mistakenly attached to the dupes because if your newly-created dupe is deleted, the cascading deletes could wipe out valuable information.
- Do a vlookup to find out if any of the related tables currently point to the dupe records. Hopefully not. If they do, you need to move the related records' pointer to the original (non-cloned) record. This is fun in and of itself.
- If there is any information of value to be fished out of the dupes, do that now. This is almost entirely a manual process.
- Once the original (non-cloned) records are the “high water mark” for information value, you're ready to remove the dupes.
- During this dupe-deletion cycle, turn off all related triggers and workflows. Don’t forget to turn them back on when you are done.
- Create a tally report (using a DIFFERENT TOOL than what you use for data manipulation, as a cross-check) of the record IDs to be deleted. Double-check that you've got the right list, and that the theory you developed in the first bullet proves out no matter how you look at the data.
- Remove a few of the dupes and examine their related records. You are looking for any error messages or weird updates that might occur. If nothing surprising happens, remove a portion of your dupes (say, 25 percent). Do it in phases – never remove all the dupes at once.
- Delete those records, but make sure you keep a copy of the original UOID (so that if you have to, you can go find that data in your dupe backup you did at the beginning).
- Keep all the files (including success/failure output files) and notes for this process in a single ZIP file, and put it in your data archive. Permanently.
Page Break
When dupe Accounts can’t or shouldn’t be merged
Thanks to mergers, acquisitions and divestitures, as well as other facets of corporate legal and finance actions, a Fortune 100 enterprise may be represented as dozens or even hundreds of accounts in the CRM system. This is an even more severe issue with the business units of Japanese keiretsu. If your CRM is integrated with the accounting, contracts and distribution systems, every new ShipTo and BillTo address might spawn a new account. And you may not be able to do anything about it, so you need to develop a strategy that doesn’t involve record merges.
The root cause is a flawed or out-of-date account hierarchy in SFDC. Salesforce’s Parent Account and Division features allow for several levels of Account (beware: you really need to read the docs on these features to figure out if they will work for you!). Use these features to group Accounts into a manageable, logical hierarchy. For most U.S.-based companies there are solid solutions for identifying corporate parents. Unfortunately, this information gets sketchy in Europe and quite murky in EMEA, but, generally, here's how to handle the “we can’t delete the multiple accounts” problem:
- Create policies and practices around using "official sources" for company names and parent-child relationships.
- Populate account records from these official sources.
- Create a new field on the account record to store the "friendly" or "street" name for a company. That way, the system-standard field can be used for the formal corporate entity that nobody will spell correctly (e.g., “E. I. du Pont de Nemours and Company”), and the friendly name (DuPont) that humans will use.
- Turn off the "create" privilege for Accounts for most users.
- Train users; explain the method behind the madness.
- Use DUNS, Experian, AM Best, or other corporate entity ID standards as a foreign key for account records. For companies outside the U.S., do your homework to find the best source for corresponding names and ID numbers (this will be different for each country).
- Create new Account records as needed to represent the entire corporate hierarchy using "parent" and "ultimate parent" pointers from DUNS, Experian, AM Best, or others.
- Rework your integrations so they don't create spurious account records.
- Clean up your database, flagging questionable records until they fit the new model. Don't hide the dirty records entirely, as that's an invitation for dupe creation by users.
Page Break
Dealing with individual dupes
It would be nice if fixing just a few duplicate records were as easy as fixing simple data quality problems. But dupes aren’t a simple problem because they involve an identity crisis: which of the dopplegangers has better data? Which of the pair (or trio) should be the surviving record? What are the repercussions of deduping?
The most important things to remember:
- There is no “undo” from a bogus merge. It’s manual reconstructive surgery and some data will be irretrievably lost. If you’re lucky, that data won’t matter.
- Merging a contact is pretty low-risk, and merging leads is even safer.
- Merging an account is much more likely to entail real risk, multiplied exponentially by any external integrations you have with your system. There are many cases where merging accounts isn’t the right thing to do and there are several reasonable alternative solution strategies (as discussed above). So…be really sure you need to go down the merge path!
- If you possibly can, do merges in a sandbox first, so you can see the first-level repercussions before you do it with live data. Even if you’ve done it in a sandbox first, do some test merges (with junk data) in the production system to make sure that systems integrated with your CRM aren’t going to react in nasty ways.
- A merge in SFDC preserves all “related lists” (child or related records) from both of the merged records. But for the fields within the two records being merged, only one value per field can be preserved. If you need to preserve or concatenate data from the “victim” record into the surviving one, you’ll have to do that manually after the fact (which means you need to be prepared before the merge).
For the moment, Salesforce’s classic UI has more flexibility in its merging features than Lightning does. At some point, Lightning will be better, but since you need to do your merging today, I’m going to describe how to get things done in classic.
In the system’s data import wizards, there's a way to look for duplicates based on email address and other items. In addition, there is the built-in duplicate detection/prevention feature that can be set up with clever parameters to block (or at least flag) dupes. These work fine, but you'll find some dupes still get through (for example, “GM” vs “General Motors” or “John Jones” vs “Jack Jones”).
Finding the onesy-twosy dupes is typically done with spreadsheets and formula fields, looking for things like string matches on email address, phone, company name or website URL. If things get subtle, you’ll want to use Microsoft’s free fuzzy matching tool (described here).
Deduping Leads
- Open a notepad or textedit instance on your desktop. You’ll need this for a scratch pad.
- Log the names and ID numbers of the records you’re going to merge and the reason why. You will want this “intention log” when somebody invariably questions why their record disappeared.
- Get to one of the dupe Leads by using SFDC’s search bar.
- Look near the top of the page for the button labeled “Find Duplicates” and push it. (If the button isn’t there, put it in the Lead page layout and make sure you have the “delete” and “modify all data” permissions on the Lead object.)
- The first step of the Find wizard lets you select which fields to match on. Adjust to your needs.
- You’ll be presented with a list of potentially matching Leads, Contacts, Accounts and Opportunities. These are all helpful for context, but the only thing you can actually merge from this page will be Leads.
- Select the Leads (two or three of them) you want to merge and click the “Merge Leads” button.
- You’ll be presented with two or three columns of data, showing the fields that are the same and those that are different between/among the records.
- The first row indicates which will be the Master (surviving) record. Typically, choose the record that was created first, or at least created by the most relevant person.
- In other rows, if you’re not given the choice, the data is bitwise identical. If you are given a choice, choose the best data.
- What if you need to preserve both values (e.g., a second mobile phone number or third email address)? Copy/paste the values you need to preserve into your scratch pad.
- Once you’re really sure you’ve selected the right things, hit the Merge button.
- Edit the surviving Lead if needed to paste the data from your scratch pad into the relevant field(s). Don’t forget to hit the Save button in SFDC.
- Save your scratch-pad/intention log under a unique name and put it somewhere safe.
- But…but…what if you wanted to merge a Lead into a Contact? In that case, you’ll need to NOT hit the Merge Lead button and instead go through the Convert Lead wizard and then merge the resulting Contact afterwards.
Deduping Contacts
- As with deduping Leads, you'll want to open a notepad or textedit instance on your desktop to use as a scratch pad.
- Again, log the names and ID numbers of the records you’re going to merge, and the reason why.
- Using SFDC’s search bar to navigate to one of the dupe Contacts. Click on the record’s Account field to take you up to that level.
- Hopefully, all of the Contacts you want to merge are listed under that Account. If not, you’ll have to navigate to those other Contacts and move them (one by one) to the Account you’ll be working with. Simple, huh?
- From the Account page (that now contains all the Contacts you want), click on the “Merge Contacts” button. (If the button isn’t there, put it in the Account page layout and make sure you have the “delete” and “modify all data” permissions on the Contact object.)
- The first step of the wizard lets you select which Contacts (two or three of them) you want to merge. Do that and click the “Next” button.
- You’ll be presented with two or three columns of data, showing the fields that are the same and those that are different between/among the records.
- The first row indicates which will be the Master (surviving) record. Typically, choose the record that was created first, or at least created by the most relevant person.
- In other rows, if you’re not given the choice, the data is bitwise identical. If you are given a choice, choose the best data.
- What if you need to preserve both values (e.g., a second mobile phone number or third email address)? Copy/paste the values you need to preserve into your scratch pad.
- Once you’re really sure you’ve selected the right things, hit the Merge button.
- Edit the surviving Contact if needed to paste the data from your scratch pad into the relevant field(s). Don’t forget to hit the Save on the Contact.
- Save your scratch-pad/intention log under a unique name and put it somewhere safe.
Deduping Accounts
- Follow the steps above for opening a scratch pad, logging names and IDs and explanations.
- Go the Accounts’ “home page” and scroll to the bottom of that overview page. Look in the “Tools” section for the “Merge Accounts” link. Click on that.
- The first step of the wizard lets you search for companies. The only way you can do that is by name. If the dupes have different names, you’ll need to rename the “victim” (non-surviving) company so it’s similar enough to be found with a simple string search. Click the “Find” button.
- The next step of the wizard lets you select which Accounts you want to merge. Do that and click the “Next” button.
- You’ll be presented with two or three columns of data, showing the fields that are the same and those that are different between/among the records.
- The first row indicates which will be the Master (surviving) record. Typically, choose the record that was created first, or at least created by the most relevant person.
- In other rows, if you’re not given the choice, the data is bitwise identical. If you are given a choice, choose the best data.
- What if you need to preserve both values (e.g., notes or business description)? Copy/paste the values you need to preserve into your scratch pad.
- Once you’re really sure you’ve done the right things, hit the Merge button.
- If needed, edit the surviving Account to paste the data from your scratch pad into the relevant field(s). Don’t forget to Save the Account when you’re done.
- Save your scratch-pad/intention log under a unique name and put it somewhere safe.
Deduping other tables
SFDC doesn’t provide wizards for deduping other objects, but with a small amount of code (cut/pasted into SFDC’s Developer Console and its lovely Execute Anonymous window), you can leverage SFDC’s merge DML operation, which works for Cases, Opportunities, Solutions, and Tasks. The merge call is pretty limited (it doesn’t give you any field-by-field selection, just letting you choose the surviving record), so you’ll definitely want to have a full backup copy of the victim record in your scratch pad so you can edit any fields where the surviving record didn’t hold the best data.
For tables that go beyond those listed above, you’ll have to figure out a different strategy: true merges aren’t available, but there are lots of tricks you can do with clever editing and DML. Have fun with that (but be careful!).
Page Break
Microsoft's free fuzzy matching plug-in
If you’re on a PC and you’re using conventional Office, have we got a deal for you: a tool that helps you quickly find good matches using fuzzy logic, with parameters and options galore. This guide will get you started, using Lead importing and dupe-detection as an example…but this tool is good for any of the objects in SFDC.
The Fuzzy Lookup add-on is available for download here.
Step 1: Setup
Once you've downloaded the Fuzzy Lookup add-on, open Excel. If there is a ribbon for Fuzzy Lookup, continue to step 2. If not, activate the add-on by navigating to Options and Add-ons. (Note: different versions of Excel have slight variations in the UI/navigation sequence. If your version doesn’t match what you see here, Google your version for instructions on how to get these steps done.)
 David Taber/IDG
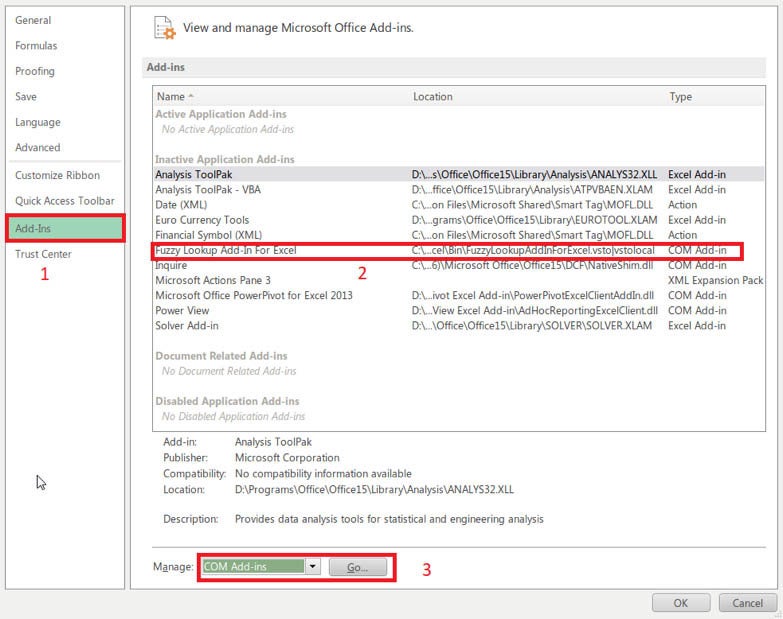
David Taber/IDGOnce in options, navigate to Add-ins (1),
Check (2) to make sure the fuzzy lookup plugin is both installed and inactive, and
Use the dropdown in (3) to manage COM Add-ins.
 David Taber/IDG
David Taber/IDGHit Okay and check to make sure the Fuzzy Lookup ribbon has appeared.
 David Taber/IDG
David Taber/IDGStep 2: Data input
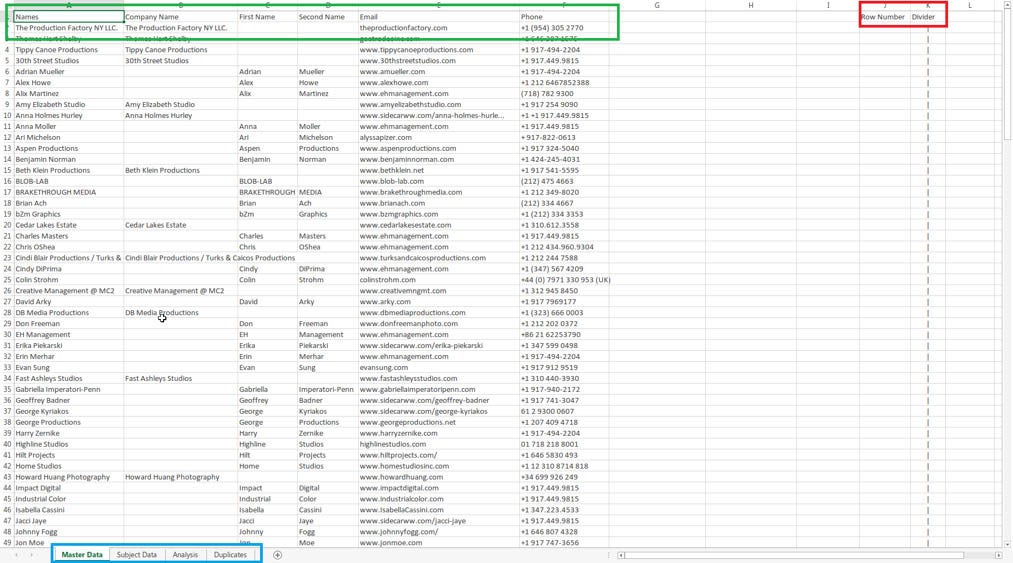
Create four sheets in a new workbook. Name the first Master Data, the second Subject Data, the third Analysis and the fourth Duplicates.
The Master Data sheet will eventually hold your deduplicated data, the data that will be uploaded into Salesforce. Begin by taking a single data set that has been internally deduplicated and insert it into the Master Data spreadsheet. Add in two columns, one for Row Number and one for Divider. Leave the row number blank for now, include some visual aid in the divider column.
 David Taber/IDG
David Taber/IDGRepeat the process for Subject Data in a second worksheet. Next, normalize the columns of the Master Data with that of the Subject Data (if you’re lucky, they’re identical…but never assume that). In the example, the Subject data has the following headers:
 David Taber/IDG
David Taber/IDGAnd the Master has the following:
 David Taber/IDG
David Taber/IDGNotice the “Email” in the Master Data is actually a “Website” column, and in the Subject Data the “Website” column has phone numbers, and the “States” column has city names. Make sure the contents of the Master and Subject columns agree, as in this example:
 David Taber/IDG
David Taber/IDGNotice the headers are also in the same columns. If necessary, copy and paste columns in either data set to make sure the two worksheets agree. This will aid in the merge of the data sets later.
 David Taber
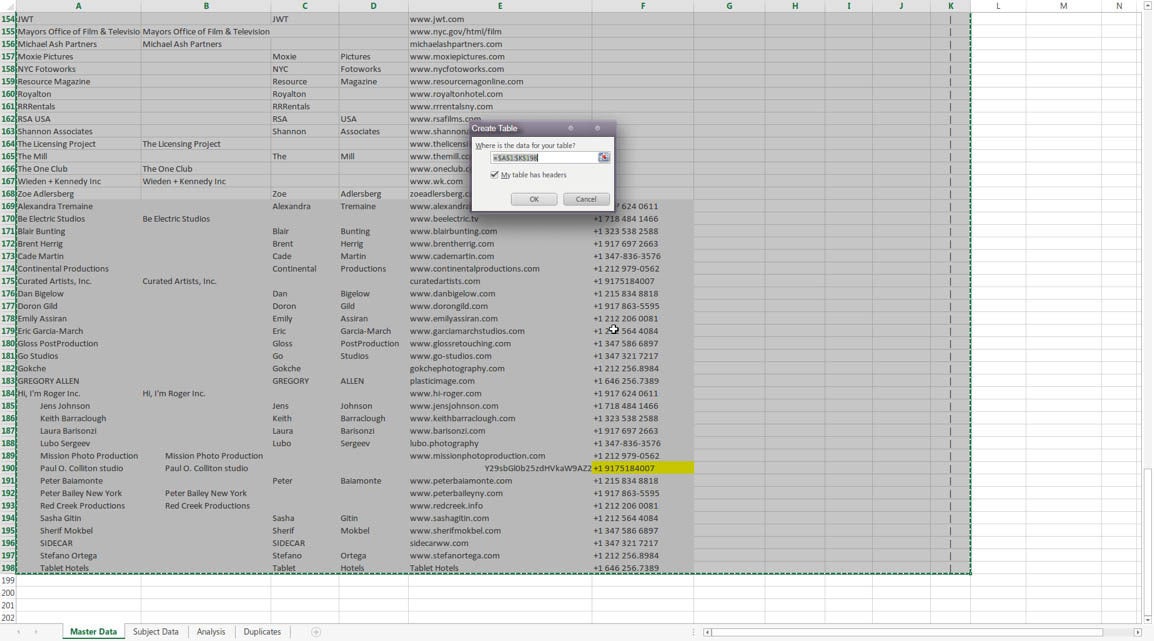
David TaberStep 3: Table Creation and Analysis
For both Master and Subject worksheets, select the entire data set (but none of the empty rows and including the Divider row) and input Ctrl-L to create a table. Select “My Table has Headers,” and hit OK.
 David Taber/IDG
David Taber/IDGNext, select the first row of the Row Number column, and input “=ROW(”. You can then select Column A Row 2, which should input the text “[@Names]” or something similar. Close the parentheses on the “=ROW(” formula and hit enter. Row numbers should appear in that column for the whole table. This will be useful for reference later.
 David Taber/IDG
David Taber/IDG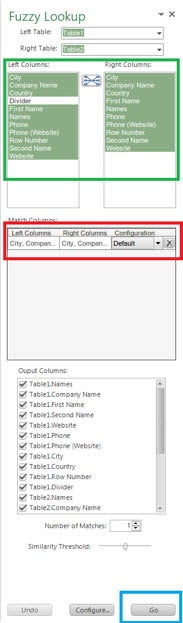 David Taber/IDG
David Taber/IDGNavigate to the Analysis tab and place your cursor on A1. Open the Fuzzy Lookup add-on from the ribbon.
Hit the x to clear the default configuration.
Set up a new configuration, matching the columns with the same name, minus the phone numbers and any data columns that were added to the Master sheet (i.e., are blank in Master), and click the configuration button to create the configuration. Do the same with the phone number columns. Select default configuration for the first and PhoneNumber configuration for the second, as in the screenshot below. There are further configurations for Zip Codes, which can be used if applicable.
 David Taber/IDG
David Taber/IDGClick GO to run the fuzzy matcher.
Step 4: Analyze data and dedupe
Select the Similarity header and navigate to Data > Filter. Select the chevron next to Similarity and filter out the 0 values.
 David Taber/IDG
David Taber/IDG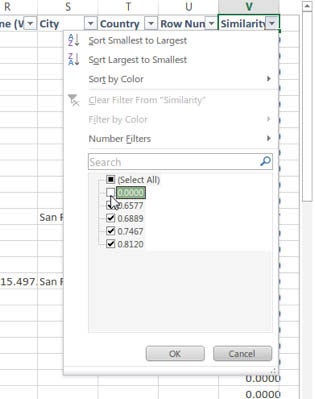 David Taber/IDG
David Taber/IDGAfter hitting Ok, the data with a similarity of 0 will be filtered. What will be left are the records that the system thinks are duplicated based on the parameters set.
The Similarity column shows the confidence the system has of those records being duplicates.
The left of the Divider row is the Master Dataset and the right is the Subject Dataset.
Merge the datasets from the right of the divider to the left of the divider. Once done, use the Row Number reference on the left of the divider to find the correct row in the Master data set and copy the merged data into the Master dataset in that location.
 David Taber/IDG
David Taber/IDGThen use the Row Number on the right of the divider to find the same row in the Subject dataset, and remove that row, shifting the other cells upward to close the gap and pasting the duplicate row into the Duplicates sheet. In the Subject Data sheet, delete the now-empty row to clear up the blank space.
 David Taber/IDG
David Taber/IDGFinally, copy the deduplicated data from Subject into the merged data of Master (notice the row numbers aren’t being copied).
 David Taber/IDG
David Taber/IDGYou will now have a larger Master data set that has been both deduped and merged.
 David Taber/IDG
David Taber/IDGClean up the Subject datasheet, deleting all the headers and data so it’s ready for a new table.
Repeat steps 2-4 for all the Subject Datasets you have, leaving the merged and deduped Master Data in place. When you run out of datasets, you will have deduplicated data in the Master Sheet that you can then insert into Salesforce using its built-in data Import Wizard.
Page Break
Using a mass deduping tool on SFDC records
Once you get to any size of database in SFDC, it will be essential to get some real deduping capability — way beyond what's possible with the internal wizards (described in the section on dealing with individual dupes), which are good for when you only have 10-40 records to dedupe. There are several deduping tools available, and we’re making this text as vendor neutral as possible.
There are two main categories of deduping tool — those that do things on external data sets (Excel, Access, SQL databases) and those that work directly on data while it is held in SFDC. We’ve already covered deduping as part of the import process in the section on preventing duplicate Salesforce records, now our use case is removing dupes that are nicely entrenched in your production SFDC database. By far the fastest and best way to do that is in situ using the tools that work directly against the live data. However,any time you do a lot of data manipulation in a production SFDC system, you may cause triggers, workflows, roll-up fields to be re-evaluated, and interactions with external systems may also be invoked. These can bog down the system in a big way, and may cause unforeseen consequences that are quite ugly and tough to reverse so you’ll need to test thoroughly in your specific system before you do any mass deduping, no matter how good the tools are. Almost always, during the final merge process, you’ll want to quiesce the system to the extent possible and turn off relevant triggers and workflows.
If you need to explain to others what you are doing, you probably don’t want to show them all the details below…but you can show them this “lite overview.”
The basic mass-deduping strategy:
- Sit down. Have some warm milk. Relax. This is going to take some time. Deduping is a process, not an event. And successful deduping of a big, messy database will take weeks. Yes, really. Budget your time accordingly and set expectations with the people who'll need to review the merge candidates: you're going to need an hour a day of their time throughout the process. Yes, really.
- Before you start each day’s deduping, do a complete backup of your SFDC data. Every single record of every single object. Really. Saved on your servers. I know, it can take hours, even with the fastest backup tool. You'll thank me later. You can use SFDC's data export backup feature including all attachments…but iff you've already used this week's backup for other purposes (yes, SFDC allows you to use this feature only once a week), back up the data today using Data Loader, the deduping tool’s “mass backup” feature,or some other tool. Just download everything in the system, including all the history tables and chatter stuff).
- If you aren’t using SFDC Campaigns, you really should consider converting to them prior to deduping Leads and Contacts. The system’s standard Lead Source is a pick-list that can only hold one value. When you merge, if you have only the system’s Lead Sources, you’re almost certain to lose some valuable data. In contrast, Campaigns will preserve all the historical “touch” data for you (and enable a “touch history” that is valuable to marketers). Converting to Campaigns is a nice big spreadsheet exercise: examine all the Lead Sources in the system, create a campaign for every Lead Source currently in use, and then create campaign members for each Lead, Contact, Account, and Opportunity in the system. This can take at least an hour for every 500 Leads or Contacts you've got in the system...so budget time accordingly.
- Prior to deduping, normalize and cleanse your data so the deduping tool can do a better job of matching records. The goal is for the deduping tool to be able to use as many literal-string matches as possible so the fuzzy matching is more effective. The very first cleansing step: make sure all records are “owned” by active users, as records that aren’t have several strange behaviors (the SOQL query to find the zombie records is “SELECT id FROM <object> WHERE User.IsActive = FALSE”). Next, transform state and country strings into ISO-standard state and country codes, or at least move them to standard spelling (e.g., “USA” vs “United States”). Fix country and city codes on phone numbers (often, in European numbers there are extra zeroes that don’t apply when you’re dialing internationally). Make sure phone numbers aren't being represented as scientific notation (yes, really). Make sure postal code spacing is consistent (is it XY 12 AB or XY1 2AB or XY12AB?) and that ZIP codes are represented as text, not numbers (to avoid leading-zero suppression that makes the ZIP code for Amherst, MA look like "1002" instead of "01002"). Remove middle initials from first name fields. Handle first initials (like "J. Walter") and suffixes (like “Jr.”) in a consistent way. Standardize the way you handle compound last names (is it van der Heyden or van derHeyden or vander heyden?). Decide how you're going to handle accented and (non-ISO-Latin) characters in names, company names, street names and city names and normalize all these strings (e.g., so that forté becomes forte).
- Prior to deduping, identify fields that you'll want to preserve both the "winner" and "loser" values that both records might have right...even though they are different values (e.g., multiple phone numbers, email addresses, stage, status, owner, record type, lead score, rating, type). Once you've ID'd these vulnerable / valuable fields, create a new text-area field (it must be a text-area field) in the table you're deduping, and turn history tracking on for that field (you might want to call the new field "▼Extras" for reasons I won't explain) and use Excel concatenate formulas to generate the ▼Extras content. Due to length constraints (255 characters), you may need to create more than one Extras field. Also, create a text-area field for housekeeping information, such as “dead” ID numbers, merge details, and other information you may need in the future (yes, turn on history tracking for it, too). It’s a best practice to have the ▼Extras and ▼Housekeeping content in an XML format, for later parsing and processing, along these lines:
▼Extras
<oldUOID>00Q000324abs38b</oldUOID>;
<otherPhone>212-456-1111</otherPhone>;
<oldEmployer>NBC Universal</oldEmployer>
▼Housekeeping:
<mergeStrategy>lead2lead_pass3</mergeStrategy>;
<mergeRationale>bad import from reality TV participants</mergeRationale>;
<mergeDate>20jan17</mergeDate>;
Once you’ve got the contents right in your spreadsheet, use Data Loader or Excel Enabler to populate each record with the new contents generated from those vulnerable fields. Once these ▼Extras fields are populated, you're almost ready to start... - No, you're not. Back up ALL YOUR DATA again. Seriously. You will live to see the day when this will save your bacon.
- No, you're not ready (revisited). Back up the entire metadata model, using Eclipse. You want to make sure you can backtrack any changes you might have to make (or that some other creative admin is making) during your deduping process.
- Hopefully, you've got access to a FULL sandbox (if not, try to get someone to buy it for a month or two — it's really the only safe way!). Look in the sandbox login log to see who's been in there since the last refresh. Email each of them and ask if they have anything in there that they need to save. Before you do the refresh, backup all the sandbox data (REALLY) and use Eclipse to do a full backup of all of its metadata, in case somebody forgets to tell you about their crown jewels after you’ve erased them with the sandbox update. So now that you’ve got that Sandbox backup, do a full sandbox refresh (you only get one of these every 30 days, so you'll want to think about calendar effects for future refresh demands in the organization). On big systems, this may take days, so be patient.
- Use the full Sandbox to test each pass of deduping for each object to understand the sideeffects of merges. This is particularly true if they have external AppExchange apps installed. After you've validated the behavior in the Sandbox, you redo the exact same deduping procedure in their production system. NOTE that external apps may behave differently in production than in sandbox, so you'll still need to do some small batches of each dedupe cycle in production so you can spot the sideeffects and gotchas.
- Typically, plan to dedupe the "leaf nodes" first. This means things like Leads, Notes, and Tasks. They are the least dangerous to get wrong, and working on them will re-familiarize you with the deduping tool features and quirks, which are easy to forget.
- Almost always do Lead deduping at a single-level table first (e.g., Leads to Leads, then Leads to Contacts).
- Be very wary of deduping things that are at the top of an information tree (i.e., have lots of child and related records), no matter how tempting it may be to start there. Accounts are the most obvious case: you don't want to dedupe them until the very end due to the catastrophic impact of an erroneous merge. Although the merges are logged, they CANNOT be undone, so you better really mean it when you say "go." If you see possible dupes in the list that ought to have been caught earlier, stop and go back to understand why it wasn't trapped and fix that before you go on. Make sure that earlier de-dupe candidates aren’t being re-instantiated by some code somewhere.
- If you're deduping something that has an external data key (for example, a pointer to a record in an integrated system or an industry standard database like Dunn & Bradstreet) you need to make sure that field is visible in your deduping tool. Generally speaking, DO NOT merge records that have external keys. While they may be legitimate dupes, merging them will wreak havoc on the external pointers. You'll need to do some more serious system work to get rid of these cases, and many companies choose to leave them in place.
- For each dedupe cycle, use a whiteboard to diagram:
- What fields and rules you are going to use to match on
- What fields you need to see when looking at the match report
- What rules and criteria you are going to use to determine the "winner" (master) in the merge transaction.
- In sales organizations, the Owner of a record can be a hugely political factor in determining the winner. Make sure you've bullet-proofed your "ownership" criteria and outcomes...so that you won't have to wear a bullet-proof vest to work.
- Be REALLY careful about how you handle subsets of merge candidates (for example, oldest record wins in the general case, but that's only after a first pass of merging has been done with a primo list of leads you just collected).
- What situations should preempt merges (for example, don't merge a pair if foreign keys are present in both candidates and the external system can't tolerate merges). This one is tricky, as none of the tools handles this automatically. You’re just going to have to sit there and think.
- The order of your matching passes and merging cycles.
- Take a picture of what's on your whiteboard before you erase it for the next dedupe pass, and save that picture in your dedupe log book.
- Set up the dedupe tool to append/combine the ▼Extras fields and any other long-text fields in your table. If your tool doesn’t have this feature, you’ll have to do this as an Excel exercise after the merge.
- Never blindly accept a merge result set; always scan at least three fields for each record to find typos, obsolete email domains, abbreviations and mismatches. Talk with the users and you may find there are a number of additional fields you need to look at (e.g., owner, territory, status) to detect problems.
- Involve a user representative in approval of each merge set before you do the deed! Do a trial run of the merge-candidate logic with a large representative set of records. Divide this set up into batches of no more than 2000 records and distribute these to end users for review (give them no more than 36 hours to get back to you). You'll need them to do a reality check on whether each of the records should be merged and which records are the “winner” in the process. EVERY TIME, create a spreadsheet export of the merge candidates. When you do this, in CRMfusion you'll need to replace column E of the spreadsheet values "28" with "winner" and "29" with nothing (aka: blank, null, nada, bubkes). Get user authorization before EVERY merge — you have no idea how many little details can get in the way.
- Now, before you start doing even your first merge, you probably want to turn off all the validation rules, workflows, and triggers for the object in question. In really big systems, there's all manner of field changes and alert emails that may be fired off by merges. Further, there are all kinds of data conditions that may cause the merge to fail (in particular, due to old data banging into new validation rules). You may also discover that Marketo or other related plug-in systems may have campaigns, scoring systems and alert emails that may fire off with merges...so talk with your local marketing automation maven to get that stuff turned off during your merge cycles.
- Do the deduping on each object in several passes, starting from the most stringent match criteria. As you relax the criteria over several passes, watch the match results to make sure you aren't getting a lot of false matches. You'll be able to select/de-select as many of the match result sets as you like, but if the exceptions are more than 25 percent of the set, you're beginning to waste time.
- The goal is to improve data quality as you remove dupes. Some deduping tools let you correct errors you might spot in the result set. If so, fix these data quality issues on the spot.
- Keep a log book of every deduping cycle you do! Best to take notes about the objective of each pass, the timing, the name of the scenario files, and the name of the log file created. At some point, you'll need to reverse some deduplication and your only hope is to have notes to reconstruct the crime so you can reverse it. Did I mention there's no undo for merges, and no backup is kept EXCEPT to reconstitute the records from the backups that you make yourself?
- With each deduping cycle, there will be a number of merge-tool settings that change. Save each and every one of these scenario and master-rule changes as a separately named file (like "Client-Leads-Pass1"). Make sure the file name is indicative of what problem you were trying to solve, as you'll never remember what you were thinking the next time you run the tool. Seriously, you'll need these!
- At the end of each deduping cycle, do any post-merge “unpacking” of the ▼Extras content you created. Since a given row may actually be merged in more than one pass, you don’t want that content to get scrambled. Typically, it’s a good idea to put all the ▼Extras and ▼Housekeeping content from prior cycles into a single hidden long-text field (yes, make it 32K characters long) called something like ▼MergeLog.
- Merging large dedupe sets takes quite a while due to computation realities and the cycle-time of web services. Budget enough time to really do the job if you've got thousands of dupes. However, do not do all of them at once; take breaks every hour or so to clear your head. If you have a large merge set, it will take a couple of minutes per 100 dupes. Get up, walk around. Seriously, breathing and pacing increases your IQ and prevents silly errors.
- Note that most deduping tools’ fuzzy matching process is very CPU intensive and suffers from “combinatorial explosion” problems. In most cases, batches should be only a few thousand at a time. (I’ve done a batch of more than 20,000 and it took forever.) You’ll need to figure out a data partitioning strategy (typically, something like geographic or alphabetical) and a batch-logging system so you know where you are at all times in your data set. For really big data sets, you can have several instances of the deduping tool running in parallel (on separate machines). Typically, this is a “laptop farm” (you can’t use servers because the UI is an essential part of the deduping tool’s operation). I like using sticky-notes on each keyboard so I don’t lose track of each system’s batch and status.
- When you’re “done for the day” with merge work, don’t forget to turn triggers and workflows back on, and turn the history-tracking for your ▼Extras and ▼Housekeeping off.
- As you go through merge passes, look for patterns of duplicates and identify the situations in which they occur, the kinds of errors or formatting problems, the lead sources and time stamps to help identify the original source of the duplication. After you get familiar with your data set, the duplicate sets will have an identifiable fingerprint that helps isolate which user behavior (a result of a usability or training issue), business process, internal code, external source is causing the creation of dupes. Keep a list of these items to fix when you’re done with the deduping, because, well, you don’t want to have to do this forever.
Expect that deduping is a process, not an event. It's a gradual improvement in data quality, and the best practice is to hit the database at least every couple of weeks to identify new problems. Documentation of your dedupe cycles also facilitates training and business process improvement.